tl;dr: Do not configure Mailman to replace the mail domains in
From: headers. Instead, try out
my small new program which can make your Mailman transparent, so that DKIM signatures survive.
Background and narrative
DKIM
NB: This explanation is going to be somewhat simplified. I am going to gloss over some details and make some slightly approximate statements.
DKIM is a new anti-spoofing mechanism for Internet email, intended to help fight spam. DKIM, paired with the DMARC policy system, has been remarkably successful at stemming the flood of joe-job spams. As usually deployed, DKIM works like this:
When a message is originally sent, the author's MUA sends it to the MTA for their
From: domain for outward delivery. The
From: domain mailserver calculates a cryptographic signature of the message, and puts the signature in the headers of the message.
Obviously not the whole message can be signed, since at the very least additional headers need to be added in transit, and sometimes headers need to be modified too. The signing MTA gets to decide what parts of the message are covered by the signature: they nominate the header fields that are covered by the signature, and specify how to handle the body.
A recipient MTA looks up the public key for the
From: domain in the DNS, and checks the signature. If the signature doesn't match, depending on policy (originator's policy, in the DNS, and recipient's policy of course), typically the message will be treated as spam.
The originating site has a lot of control over what happens in practice. They get to publish a formal (DMARC) policy in the DNS which advises recipients what they should do with mails claiming to be from their site. As mentioned, they can say which headers are covered by the signature - including the ability to sign the absence of a particular headers - so they can control which headers downstreams can get away with adding or modifying. And they can set a normalisation policy, which controls how precisely the message must match the one that they sent.
Mailman
Mailman is, of course, the extremely popular mailing list manager. There are a lot of things to like about it. I choose to run it myself not just because it's popular but also because it provides a relatively competent web UI
and a relatively competent email (un)subscription interfaces, decent bounce handling, and a pretty good set of moderation and posting access controls.
The Xen Project mailing lists also run on mailman. Recently we had some difficulties with messages sent by Citrix staff (including myself), to Xen mailing lists, being treated as spam. Recipient mail systems were saying the DKIM signatures were invalid.
This was in fact true. Citrix has chosen a fairly strict DKIM policy; in particular, they have chosen "simple" normalisation - meaning that signed message headers must precisely match in syntax as well as in a semantic sense. Examining the the failing-DKIM messages showed that this was definitely a factor.
Applying my Opinions about email
My Bayesian priors tend to suggest that a mail problem involving corporate email is the fault of the corporate email. However in this case that doesn't seem true to me.
My starting point is that I think mail systems should not not modify messages unnecessarily. None of the DKIM-breaking modifications made by Mailman seemed
necessary to me. I have on previous occasions gone to corporate IT and requested quite firmly that things I felt were broken should be changed. But it seemed wrong to go to corporate IT and ask them to change their published DKIM/DMARC policy to accomodate a behaviour in Mailman which I didn't agree with myself. I felt that instead I shoud put (with my Xen Project hat on) my own house in order.
Getting Mailman not to modify messages
So, I needed our Mailman to stop modifying the headers. I needed it to not even reformat them. A brief look at the source code to Mailman showed that this was not going to be so easy. Mailman has a lot of features whose very purpose is to modify messages.
Personally, as I say, I don't much like these features. I think the subject line tags, CC list manipulations, and so on, are a nuisance and not really Proper. But they are definitely part of why Mailman has become so popular and I can definitely see why the Mailman authors have done things this way. But these features mean Mailman has to disassemble incoming messages, and then reassemble them again on output. It is very difficult to do that and still faithfully reassemble the original headers byte-for-byte in the case where nothing actually wanted to modify them. There are existing bug reports
[1] [2] [3] [4]; I can see why they are still open.
Rejected approach:
From:-mangling
This situation is hardly unique to the Xen lists. Many other have struggled with it. The best that seems to have been come up with so far is to turn on a new Mailman feature which rewrites the
From: header of the messages that go through it, to contain the list's domain name instead of the originator's.
I think this is really pretty nasty. It breaks normal use of email, such as reply-to-author. It is having Mailman do additional mangling of the message in order to solve the problems caused by other undesirable manglings!
Solution!
As you can see, I asked myself: I want Mailman not modify messages
at all; how can I get it to do that? Given the existing structure of Mailman - with a lot of message-modifying functionality - that would really mean adding a bypass mode. It would have to spot, presumably depending on config settings, that messages were not to be edited; and then, it would avoid disassembling and reassembling the message at at all, and bypass the message modification stages. The message would still have to be parsed of course - it's just that the copy send out ought to be pretty much the incoming message.
When I put it to myself like that I had a thought: couldn't I implement this
outside Mailman? What if I took a copy of every incoming message, and then post-process Mailman's output to restore the original?
It turns out that this is quite easy and works rather well!
outflank-mailman
outflank-mailman is a 233-line script, plus documentation, installation instructions, etc.
It is designed to run from your MTA, on all messages going into, and coming from, Mailman. On input, it saves a copy of the message in a sqlite database, and leaves a note in a new
Outflank-Mailman-Id header. On output, it does some checks, finds the original message, and then combines the original incoming message with carefully-selected headers from the version that Mailman decided should be sent.
This was deployed for the Xen Project lists on Tuesday morning and it seems to be working well so far.
If you administer Mailman lists, and fancy some new software to address this problem, please do try it out.
Matters arising - Mail filtering, DKIM
Overall I think DKIM is a helpful contribution to the fight against spam (unlike SPF, which is fundamentally misdirected and also broken). Spam is an extremely serious problem; most receiving mail servers experience more attempts to deliver spam than real mail, by orders of magnitude. But DKIM is not without downsides.
Inherent in the design of anything like DKIM is that arbitrary modification of messages by list servers is no longer possible. In principle it might be possible to design a system which tolerated modifications reasonable for mailing lists but it would be quite complicated and have to somehow not tolerate similar modifications in other contexts.
So DKIM means that lists can no longer add those unsubscribe footers to mailing list messages. The "new way" (RFC2369, July 1998), to do this is with the
List-Unsubscribe header. Hopefully a good MUA will be able to deal with unsubscription semiautomatically, and I think by now an adequate MUA should at least display these headers by default.
Sender:
There are implications for recipient-side filtering too. The "traditional" correct way to spot mailing list mail was to look for
Resent-To:, which can be added without breaking DKIM; the "new" (RFC2919, March 2001) correct way is
List-Id:, likewise fine. But during the initial deployment of outflank-mailman I discovered that many subscribers were detecting that a message was list traffic by looking at the
Sender: header. I'm told that some mail systems (apparently Microsoft's included) make it inconvenient to filter on
List-Id.
Really, I think a mailing list ought not to be modifying
Sender:. Given
Sender:'s original definition and semantics, there might well be reasonable reasons for a mailing list posting to have different
From: and and then the original
Sender: ought not to be lost. And a mailing list's operation does not fit well into the original definition of
Sender:. I suspect that list software likes to put in Sender mostly for historical reasons; notably, a long time ago it was not uncommon for broken mail systems to send bounces to the
Sender: header rather than the envelope sender (SMTP
MAIL FROM).
DKIM makes this more of a problem. Unfortunately the DKIM specifications are vague about what headers one should sign, but they pretty much definitely include
Sender: if it is present, and some materials encourage signing the absence of
Sender:. The latter is Exim's default configuration when DKIM-signing is enabled.
Franky there seems little excuse for systems to not readily support and encourage filtering on
List-Id, 20 years later, but I don't want to make life hard for my users. For now we are running a compromise configuration: if there wasn't a
Sender: in the original, take Mailman's added one. This will result in (i) misfiltering for some messages whose poster put in a
Sender:, and (ii) DKIM failures for messages whose originating system signed the absence of a
Sender:. I'm going to mine the db for some stats after it's been deployed for a week or so, to see which of these problems is worst and decide what to do about it.
Mail routing
For DKIM to work, messages being sent
From: a particular mail domain must go through a system trusted by that domain, so they can be signed.
Most users tend to do this anyway: their mail provider gives them an IMAP server and an authenticated SMTP submission server, and they configure those details in their MUA. The MUA has a notion of "accounts" and according to the user's selection for an outgoing message, connects to the authenticated submission service (usually using TLS over the global internet).
Trad unix systems where messages are sent using the local sendmail or localhost SMTP submission (perhaps by automated systems, or perhaps by human users) are fine too. The smarthost can do the DKIM signing.
But this solution is awkward for a user of a trad MUA in what I'll call "alias account" setups: where a user has an address at a mail domain belonging to different people to the system on which they run their MUA (perhaps even several such aliases for different hats). Traditionally this worked by the mail domain forwarding incoming the mail, and the user simply self-declaring their identity at the alias domain. Without DKIM there is nothing stopping anyone self-declaring their own
From: line.
If DKIM is to be enabled for such a user (preventing people forging mail as that user), the user will have to somehow arrange that their trad unix MUA's outbound mail stream goes via their mail alias provider. For a single-user sending unix system this can be done with tolerably complex configuration in an MTA like Exim. For shared systems this gets more awkward and might require some hairy shell scripting etc.
edited 2020-10-01 21:22 and 21:35 and -02 10:50 +0100 to fix typos and 21:28 to linkify "my small program" in the tl;dr
comments

 Like
Like  A new release 0.2.3 of the
A new release 0.2.3 of the  Here is my monthly update covering what I have been doing in the free software world during December 2020 (
Here is my monthly update covering what I have been doing in the free software world during December 2020 (




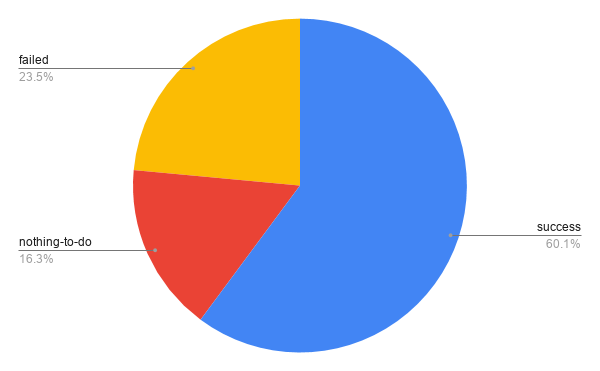
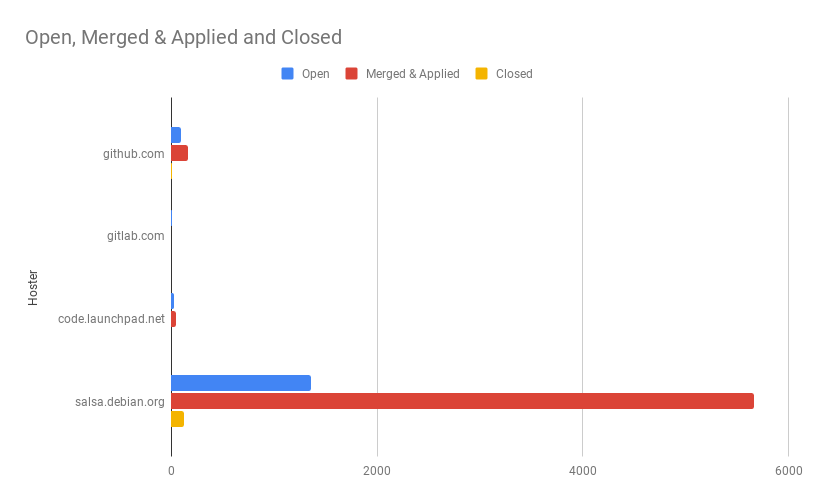 In this graph, Open means that the pull request has been
created but likely nobody has looked at it yet. Merged
means that the pull request has been marked as merged on
the hoster, and applied means that the changes have ended
up in the packaging branch but via a different route (e.g. cherry-picked or
manually applied). Closed means that the pull request was closed without the
changes being incorporated.
Note that this excludes ~5,600 direct pushes, all of which were to salsa-hosted repositories.
See also:
In this graph, Open means that the pull request has been
created but likely nobody has looked at it yet. Merged
means that the pull request has been marked as merged on
the hoster, and applied means that the changes have ended
up in the packaging branch but via a different route (e.g. cherry-picked or
manually applied). Closed means that the pull request was closed without the
changes being incorporated.
Note that this excludes ~5,600 direct pushes, all of which were to salsa-hosted repositories.
See also:
 This is a follow-up from the blog post of Russel as seen here:
This is a follow-up from the blog post of Russel as seen here: 
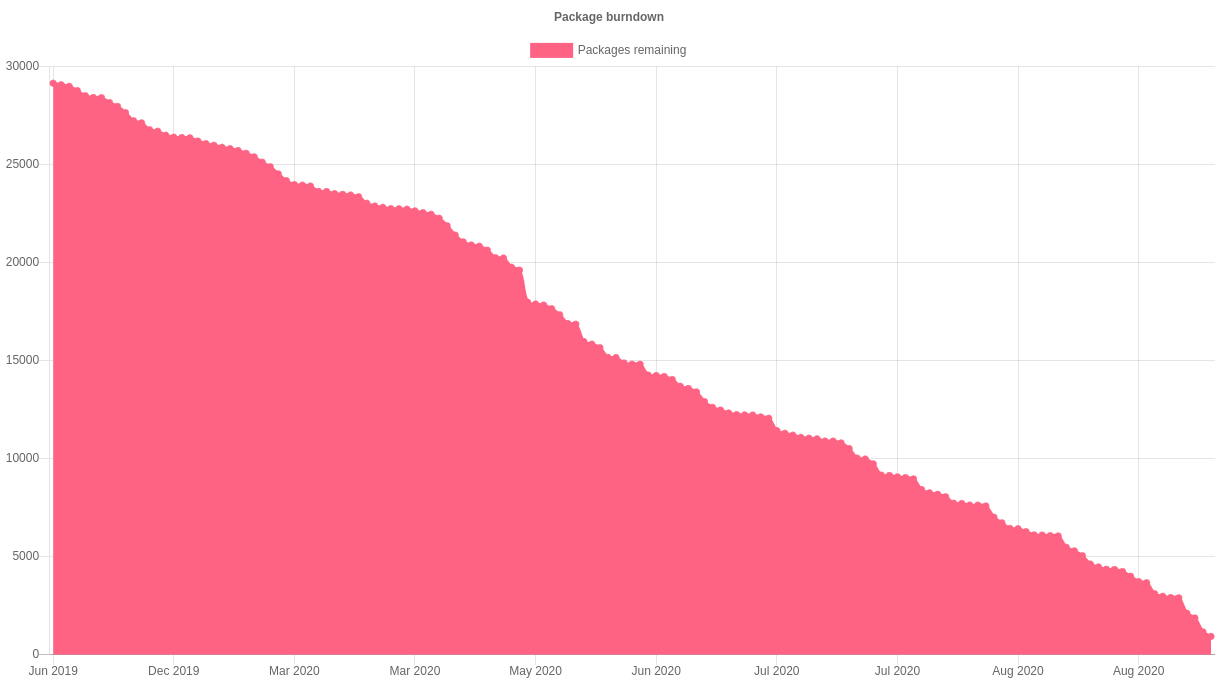
 Now that the entire archive has been processed, packages
are prioritized based on the likelihood of a change being
made to them successfully.
Over the course of its existence, the Janitor has slowly
gained support for a wider variety of packaging methods.
For example, it can now edit the templates for some of
the generated control files. Many of the packages that
the janitor was unable to propose changes for the first
time around are expected to be correctly handled when they
are reprocessed.
If you re a Debian developer, you can find the list of improvements
made by the janitor in your packages by going to
Now that the entire archive has been processed, packages
are prioritized based on the likelihood of a change being
made to them successfully.
Over the course of its existence, the Janitor has slowly
gained support for a wider variety of packaging methods.
For example, it can now edit the templates for some of
the generated control files. Many of the packages that
the janitor was unable to propose changes for the first
time around are expected to be correctly handled when they
are reprocessed.
If you re a Debian developer, you can find the list of improvements
made by the janitor in your packages by going to

